- 记录数据库相关的疑难杂症
目录
neo4j
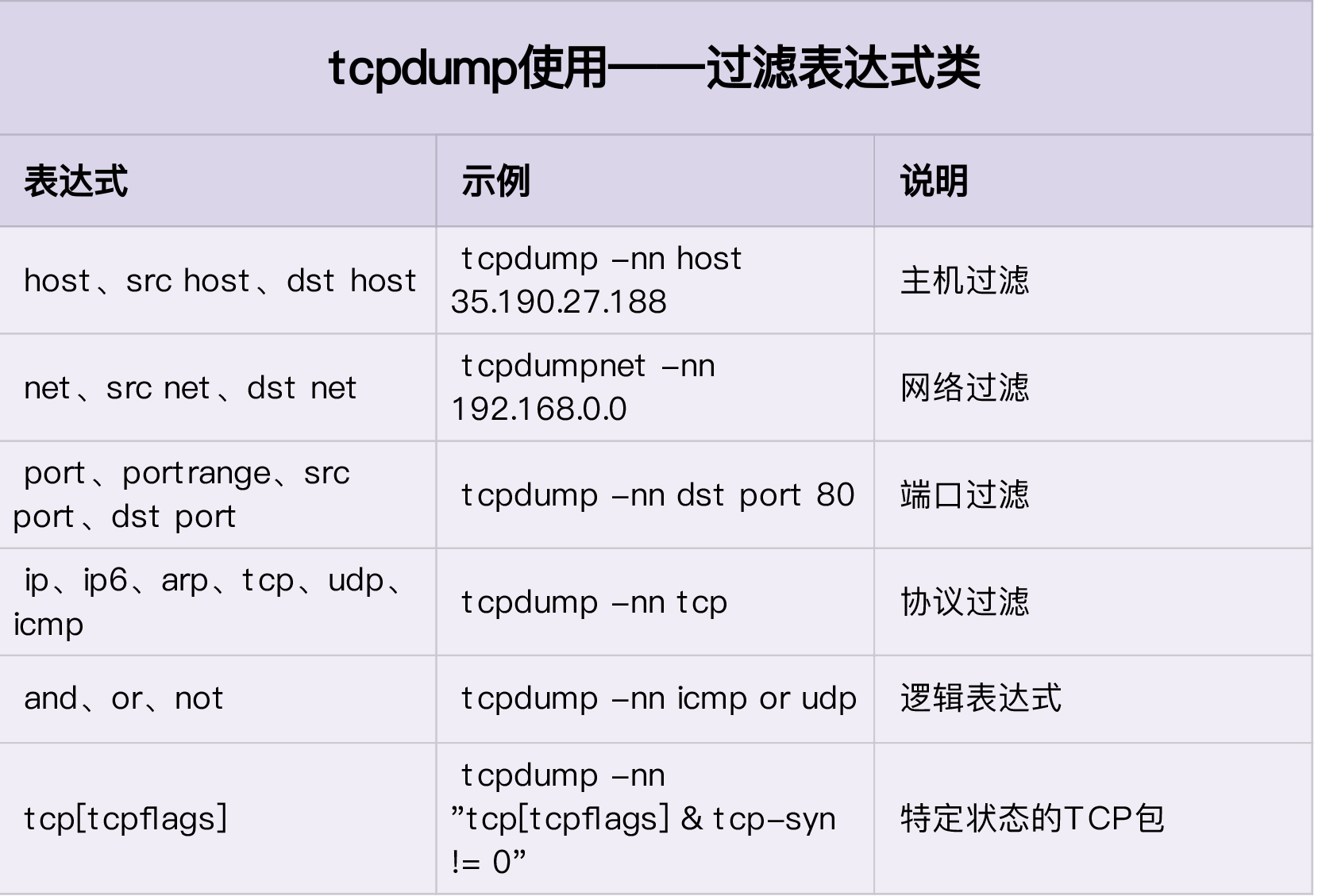
1.通讯协议:
- Q: 为什么图库使用 neo4j 的 bolt 链接协议,出现了无法找到主节点导致无法写入或者读取的问题?
- A:neo4j支持3种通讯协议:
bolt+routing(适用于集群,目前图平台不支持此协议)
bolt(适用于单机)
neo4j(适用于集群)
bolt 适用于单节点的图数据库。集群模式下的图库需要支持路由的neo4j协议进行通信,从而将请求转发到对应的数据节点上。
参考:https://neo4j.com/docs/driver-manual/1.7/client-applications/#driver-connection-uris
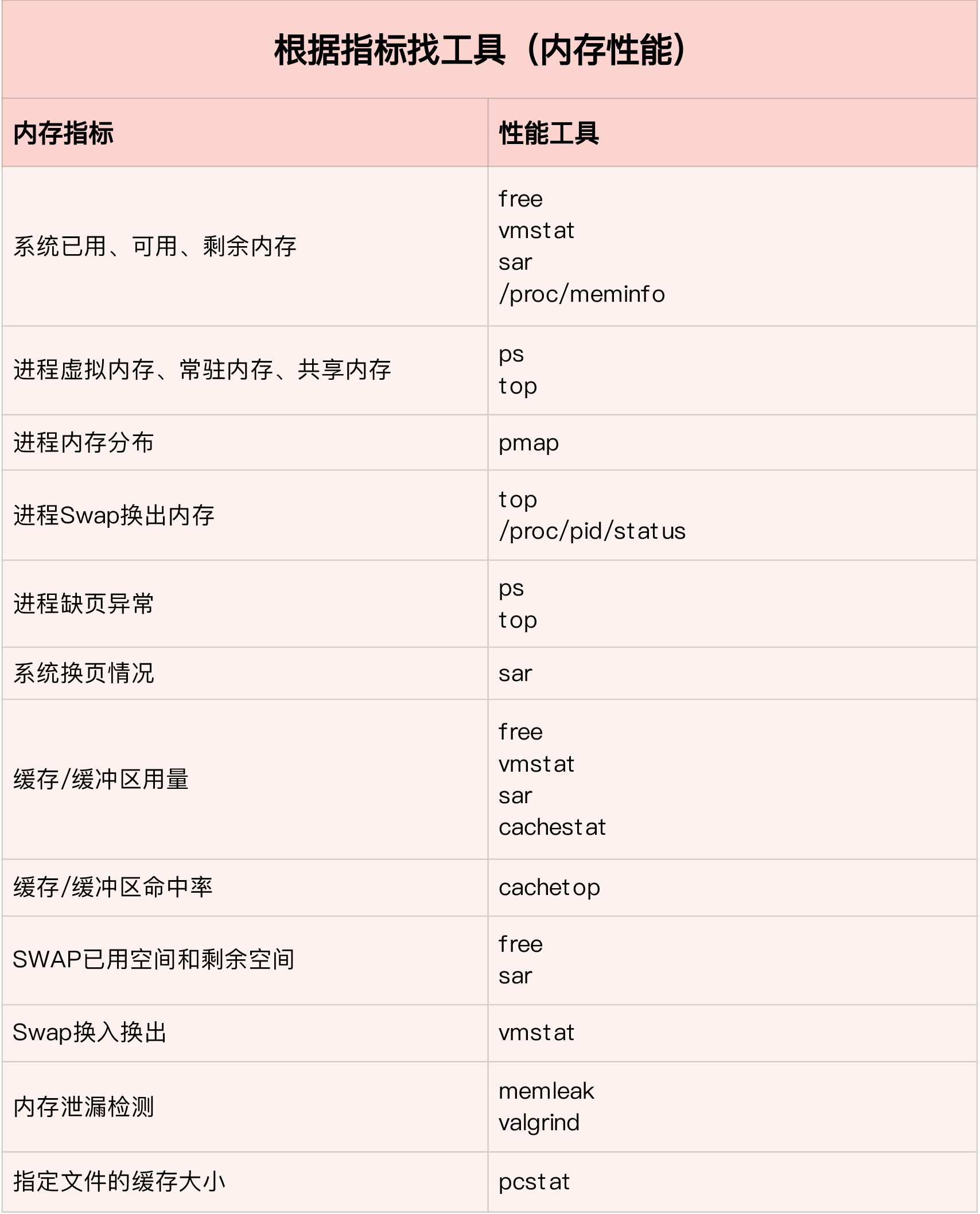
2.数据接入
- Q: 为什么出现hive数据无法接入图库?datax是否支持mysql 导入neo4j ? 什么类型的数据接入可以导入到neo4j?
- A: 不支持;不支持;目前图平台只支持文件模式导入数据到图平台
3.数据库命名规范:
- Q: 为什么出现了图数据库创建失败的问题?
- A:neo4j 有自己的数据库规范,这里需要按照neo4j的规范进行创建,所以对应的图实例也要按照规范进行校验
4.边关系查询缓慢:
Q: 为什么图析界面,点击查询边关系出现超时?
A: neo4j 4.1.x版本的图库,不支持关系边表索引建立。如图所示通过主键查询的检索模式是 AllNodesScan 全表扫描(性能调优参考:https://blog.csdn.net/qq_37503890/article/details/102073193),2亿的数据量查询的时间耗时约为10s左右。
- 解决方案:将关系边数据导入到es,通过es查询,不通过图库查询。
5.neo4j 的数据库链接泄露,句柄数量增长非常快
- A:数据库链接没有及时释放导致的数据库链接泄露,及时释放neo4j的连接即可
- 微服务句柄数量超过限制问题汇总
- A:数据库链接没有及时释放导致的数据库链接泄露,及时释放neo4j的连接即可
7.neo4j 在使用ETL导入时,出现死锁现象:
Q: 在使招行AI实验室项目中,图平台[3.1.2.69] 用spark 集群对neo4j批量导入关系边数据的时候,总是会出现报错:ForsetiClient can’t acquire ExclusiveLock(参考:https://github.com/neo4j/neo4j/issues/6248)
A:
在使用集群导数,一般是多个作业实例执行导入任务,这里就会出现并发写入的场景。neo4j的边关系写入的操作时,数据库本身会给每一个写入操作的事务分配一把排它锁(exclusiveLock),多并发写入就会出现事务之间锁的争夺情况。在实际的生产环境中观察到,最多有130个事务卡在获取锁,最后导致事务超时,整体数据导入任务失败。
解决方法是:需要降低单次事务写入数据库的数据量。单次写入大量数据非常耗时,从而降低每次事务的耗时,及时将锁资源释放出来,避免发生事务超时的死锁
提高单次事务的超时时间。避免出现多个不同事务之间的锁资源竞争时,没有足够的等待时间,导致的任务失败。
调整taurus-app配置,降低etl任务的spark executor的数量。从源头降低并发,减少锁资源竞争
调整spark配置:[ spark.dynamicAllocation.enabled false ] ,关闭 动态资源分配功能
调整 etl的spark 任务参数,限制最大:1个instances,1个cores,避免多进程并发写入导致的死锁问题
8.出现报错:Could not perform discovery. No routing servers available
- A:neo4j 的服务宕机,需要管理员维护
9.使用图平台文件导入大数据量到neo4j宕机
A: graph系统在使用文件导入120w条数据,具体表现为会出现jvm内存耗尽,机器不再接受写入请求
Q: DBA解释为cypher语句太长,堆积在内存中无法释放导致的内存耗尽,需要优化语句,建议使用unwind优化cypher语句
neo4j批量入数优化分析及实现
- 数据导入neo4j 出现 heap 堆内存溢出,表现为老年代(old gen)持续增长,不会下降
现象如下图:
- A:
neo4j批量入数优化分析及实现
使用csv文件导数到es和图库。由于csv文件非常巨大,发现2个主要问题:
导数速率很慢,单次只能写入100条数据,如果数据量在50w的实体表,一般就需要耗时1-2小时才能完成导数任务。
在实现导数的方式上有问题,批量导数实现上本质是拼接一个巨长的cypher语句,在小数据量的情况下不会有什么问题。但是如果在大数据量下,会提交很多的长语句,从而会出现neo4j图库无法及时处理这些超长的cypher语句,堆积在JVM的老年代内存中无法释放,最后neo4j出现内存OOM宕机。
优化分析:
- 在搞清原因之后,咨询DBA了解到,neo4j不建议使用长语句,最好是使用短语句来插入数据,长语句会产生堆积,进而导致内存不足。但是短语句的矛盾就在于性能低下,我们这里需要使用批量插入的模式提高性能。
- 于是在参考了neo4j-spark的源码实现,得到了启发。neo4j官方sprak的导数实现是使用批量插入的模式,不是通过拼接语句的模式。通过使用参数传递模式进行批量插入,以实体插入为例:
- scala源码实现(org.neo4j.spark.service.Neo4jQueryWriteStrategy#createStatementForNodes):
- 编译后的语句:
- with query: UNWIND $events AS event MERGE (node:Human {object_key: event.keys.object_key}) SET node += event.properties
- 这里官方实现使用了unwind关键字,这里引用 博文 解释为什么unwind可以加速插入:
- 高效的做法是利用Neo4j提供的参数(Parameter)机制和UNWIND子句:在一次数据更新中,进行一次连接,打开一次事务,批量更新数据;参数用于提供列表格式的数据,UNWIND子句是把列表数据展开成一行一行的数据,每行数据都会执行结构相同的Cypher语句。再批量更新图形数据之前,用户必须构造结构固定的、参数化的Cypher语句。当Cypher语句的结构相同时,Neo4j数据库直接从缓存中复用已生成的执行计划,而不需要重新生成,这也能够提高查询性能。
- UNWIND子句把列表式的数据展开成一行一行的数据,每一个行都包含更新所需要的全部信息,列表式的数据,可以通过参数来传递。
- 例如,定义参数events,该参数是一个JSON字符串,键events是参数名,其值是一个数组,包含两个数组元素。
1
2
3{
"events" : [ { "year" : 2014, "id" : 1}, {"year" : 2014, "id" : 2 } ]
}- 通过$events引用参数,UNWIND子句把events数组中的两个元素展开,每个元素执行一次Cypher语句,由于Cypher的语句结构固定,因此,执行计划被缓存起来,在执行数据更新任务时,参数被UNWIND子句展开,复用执行计划,提高数据更新的速度。
- 实施方法:实体数据批量插入cypher,采用overwrite模式进行数据创建和合并,依据object_key作为唯一键进行对象合并:
- 关系边数据批量插入cypher,采用overwrite模式进行数据的创建和合并,依据object_key作为唯一键进行对象合并:
{kind=link}