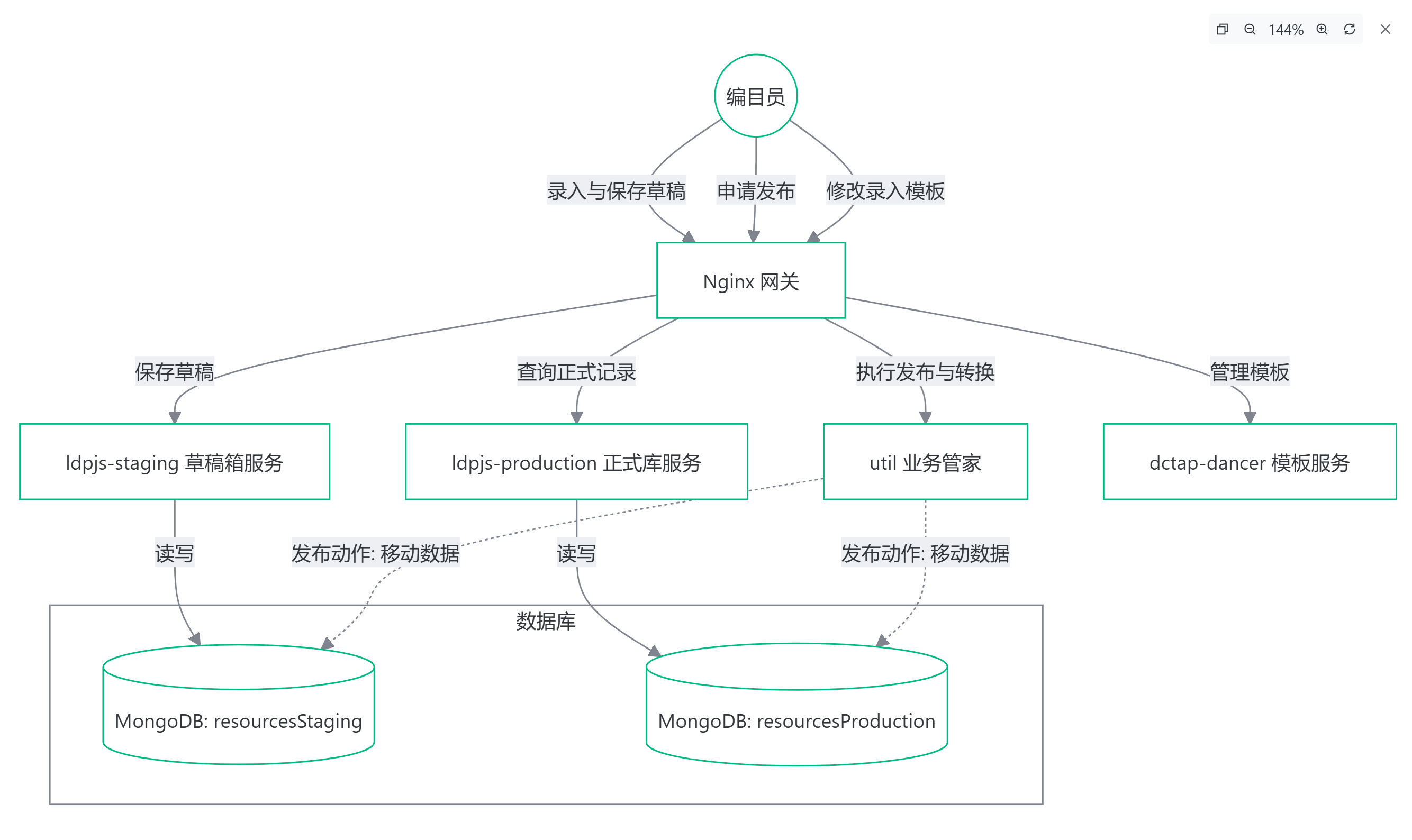
来源:@watreejane(小耳朵sir) X 平台万字实操分享 ——「摸索一年,走上出海web道路月入 4w 刀,万字记录历程,分享实操」
一、产品需求挖掘渠道
1.1 刷榜单平台
文章强调,新手必须十分熟悉知名 AI 工具榜单平台上的产品。刘小排老师曾提到,对于 Toolify 上的月度榜单产品,他熟悉到任何一个产品都是干什么的。良辰美老师更是直接用公众号的方式一个个扒榜单上的产品,执行力拉满。建议按照以下维度分析榜单产品:
- 💡 这个产品解决的是什么问题?
- 👤 用户是谁?
- 🤔 用户为什么需要它?
- 🗣️ 用户是如何评价它的?
- 🔍 它是如何找到用户的?
- 💰 它赚钱吗?多少?
- 🧠 我从这个产品身上学到了什么?
- 🤔 它的什么做法不容易?
- 🎉 我能做出来吗?
| 平台名称 | 地址 | 说明 |
|---|---|---|
| Toolify | https://www.toolify.ai/ | AI 工具榜单,月度榜单产品必看 |
| TAAFT | https://www.theresanaiforthat.com/ | AI 工具导航站,流量大 |
| Traffic.cv | https://www.traffic.cv/ | 网站流量分析平台 |
| SaaSHub | https://www.saashub.com/ | SaaS 产品目录 |
| AIBase | https://www.aibase.com/ | AI 产品数据库,可提交产品 |
| AIToolsDirectory | https://aitoolsdirectory.com/ | AI 工具目录,支持提交 |
| TopAI.Tools | https://topai.tools/ | AI 工具掘榜站,支持提交产品 |
| Product Hunt | https://www.producthunt.com/ | 全球最大的新产品发现社区 |
| Hacker News | https://news.ycombinator.com/ | 技术创业社区,可发布产品 |
| BetaList | https://betalist.com/ | 早期创业产品发布平台 |
| V2EX | https://www.v2ex.com/ | 中文技术社区,可发布产品 |
| 小众软件 | https://www.appinn.com/ | 优质软件推荐站,可提交产品 |
| IndieHackers | https://www.indiehackers.com/ | 独立开发者社区,可发布产品 |
1.2 产品提交导航站
文章提到多个支持付费推广的导航站,其中 Toolify 推广费 99 美金,TAAFT 不超过 100 美金。这类平台可以短时间内验证需求、获取流量,是出海产品初期非常重要的推广渠道。
| 平台 | 提交链接 | 推广费用 |
|---|---|---|
| SaaSHub | https://www.saashub.com/services/submit | 支持付费推广 |
| AIBase | https://app.aibase.com/zh/submission | 免费提交产品 |
| AIToolsDirectory | https://aitoolsdirectory.com/submit-tool | 免费提交工具 |
| TopAI.Tools | https://topai.tools/submit | 免费提交产品 |
| Toolify | https://www.toolify.ai/ | 99 美金/推广 |
| TAAFT | https://www.theresanaiforthat.com/ | 约 100 美金 |
1.3 日常需求记录与新词抓取
文章强调养成日常随时记录需求的习惯,这是来自 Pieter Levels(推特上知名独立开发者)的方法。他还写过一本叫做《Make》的书籍,在圈内广为流传。
具体做法:每天逼自己记录需求,比如至少 3 个以上,还是想不出需求?本质上还是没有养成思维习惯。只要做个有心人,你真的有做不完的需求,比如多多留意来自于你日常的一些抱怨、痛点,无论是生活上的烦恼,还是工作上的一些不方便的地方,甚至是在你娱乐刷视频、打游戏的时候。
新词:指新的 AI 模型名称,或围绕着新出模型的周边 AI 工具服务。这是新人弯道超车的机会。
- 多关注头部 AI 自媒体账号,日常刷推特,刻意喂算法相关内容
- 可以辅助一些 AI 工具,让 AI 持续监测相关领域新闻消息
- 准备一套专业的 Starter Kit,每次上站形成一套高效 SOP
- Openclaw 可以从捕捉产品机会、搭建产品、上站全流程自动化
1.4 需求真伪验证与产品思维
文章重点推荐了刘小排老师的《如何获得产品 idea》,流传甚广的新手必读经典。新手遵从以下四点:
- 满足自己的需求(eat your own dog food)
- 留意市场成熟产品,思考如何做出不一样的差异化(性价比更高?体验更好?)
- 万能公式:什么人,在什么场景下,愿意花多少钱,解决什么问题?
- 心法测试:假设产品来自你不喜欢的人,你还会付费吗?如果是,多半是真需求
二、流量与推广渠道
2.1 免费推广平台
Reddit 被称为”金矿”,欧美用户占比高,引流效果好。作者实践证明,在相关社区里,网站被用户自发传播,信息传递效率很快。关键技巧包括:
- 不要一来就发链接帖,先主动评论爆款帖、发求助帖,逐步试探
- 先用纯文本链接试探,爆了再改为超链接
- 善用置顶和二次修改回复功能
- 如果嫌麻烦,可以直接去海外版咸鱼 Fiverr 上下单让别人帮忙传播产品
YouTube
YouTube 在海外相当于视频版 Google,用户不懂的问题直接去 YouTube 搜索。可通过发布 Shorts 和在热门视频评论区引流。一个腰部的 AI 博主能带来持续几个月的订单。还可以结合代理平台 Affonso,让博主获得 50% 的佣金来促进推荐。
其他免费平台
除了 Reddit 和 YouTube,文章还提到了 Fandom 粉丝社区、Hacker News 讨论帖等都可以用类似方式引流。林悦己的观点是”什么来流量搞什么,不局限一种方式一个平台”。
2.2 付费推广渠道
Google Ads
对于上路的网站,Google Ads 是必然要尝试的。有大佬说过,SEO 在 Google Ads 面前就是弟弟,用得好的 Google Ads 像印钞机。要注意的坑包括:
- 选择国家时一定要慎重(选定后无法修改)
- 尽早安装统计代码(建议用 Tag Manager)
- 14 天 ROAS 才是真实广告收益
- 前半个月不要着急看收益,给 Google 足够调优时间
- 可以联系 Google ads 顾问获取免费指导
Fiverr 外包传播
海外版”咸鱼” Fiverr 可以下单让别人帮忙传播产品,起码增加一些确定性,适合不想自己花时间操作的人。
三、SEO 与网站技术工具
3.1 SEO 实操工具
文章强调 SEO 核心围绕关键词、外链、产品体验三大方面,不断向 Google 证明自己的网站。关键词策略是”一个关键词一个页面”,用长尾关键词搜刮流量赢得谷歌信任,再逐步覆盖主关键词(农村包围城市)。外链建设要坚持发,内链建设是帮助 Google 理解网站结构和权重分布。网站性能指标建议用 PageSpeed Insights 检测,各项指标 90 分以上。
新手几大坑:
- 一次性上很多网页(尤其是 AI 生成的低质量内容)
- 一上来就上多语言
- 一个页面涉及多个关键词
- 忽视内链建设
- 短时间上很多低质量甚至垃圾外链
| 工具 | 地址 | 用途 |
|---|---|---|
| PageSpeed Insights | https://pagespeed.web.dev/ | 网站性能检测,各项指标 90 分以上 |
| Google Tag Manager | https://tagmanager.google.com/ | 统计代码管理,配合 Google Ads 使用 |
| Google Ads | https://ads.google.com/ | 付费投流,快速验证需求和放大业务 |
| 外链资源列表 | https://potent-measure-31f.notion.site/14368f418f50804ba419d3ce7a333fa8 | 他人分享的外链构建资源 |
四、关键公众号与人物
4.1 文章重点提及的公众号
| 公众号/人物 | 专长领域 | 作者评价 |
|---|---|---|
| 亦仁 | 眼界、商业思维 | 教眼界,生财有术创始人,认为 App 依赖投流,出海 Web 更适合普通人 |
| 刘小排 | 产品设计、出海 Web | 教产品,其《如何获得产品 Idea》流传甚广,产品自驱动型代表 |
| 哥飞 | SEO 优化 | 教 SEO,公众号免费文章让作者 SEO 一开始没跑偏,组织出单群友分享 |
| 良辰美 | 出海实战、新词抓取 | 让作者看到希望,一年至少 100 多个网站,大力出奇迹 |
| 林悦己 | 流量获取 | 流量高手,”什么来流量搞什么,无孔不入” |
| 小耳朵(作者) | 出海 AI Web 实操 | 简介:”深知小白摆脱惯性进入正循环的不易” |
4.2 推特上值得关注的账号
| 账号/人物 | 平台 | 价值 |
|---|---|---|
| @levelsio(Pieter Levels) | X (Twitter) | 知名独立开发者,著有《Make》一书,主张日常记录需求、快速上线 MVP |
| @watreejane | X (Twitter) | 本文作者,从零到月入 4 万刀的实操经验分享 |
| 刘小排 | 公众号/X | 产品设计专家,《如何获得产品 Idea》等经典文章作者 |
| 良辰美 | 公众号/X | 出海实战派,一年至少 100 多个网站的执行力 |
五、产品开发与上线工具
5.1 Starter Kit(上线模板)
文章建议准备一套专业的 Starter Kit,行业里最出名的就是 ShipAny 和 MKSaas,然后持续打磨成最适合自己的,每次上站形成一套高效 SOP。另外提到了 Openclaw,可以从捕捉产品机会、搭建产品、上站全流程自动化。
| 工具 | 关键词 | 用途 |
|---|---|---|
| ShipAny | 搜索”ShipAny” | 出海 AI Web 上线模板,行业知名 |
| MKSaas | 搜索”MKSaas” | SaaS 产品上线模板 |
| Openclaw | 搜索”Openclaw” | 全流程自动化工具(产品机会捕捉到上线) |
5.2 支付与服务工具
| 工具/服务 | 地址 | 用途 |
|---|---|---|
| Stripe | https://stripe.com/ | 专业支付平台,更容易赢得用户信任 |
| Affonso | 搜索”Affonso” | 第三方代理平台,充值代理可拿 50% 佣金 |
| Resend | https://resend.com/ | 邮件服务(注意风控,含短时间发送频繁会被封号风险) |
| Postmark | https://postmarkapp.com/ | 邮件服务(作者封号后的替代方案) |
| Fiverr | https://www.fiverr.com/ | 海外版”咸鱼”,可下单让人帮忙传播产品 |
六、社区与学习平台
文章中反复提到”生财有术“(scys.com),这是一个重要的创业者社区,作者多次强调它对自己成长的帮助。此外还有”出海 AI web 深海圈”,作者成为刘小排老师第一期学员。刘小排老师的课程在出来之前就呼声很高,专业性和系统性让作者震撼。
| 平台/社区 | 地址/关键词 | 价值 |
|---|---|---|
| 生财有术 | https://scys.com | 创业者社区,大量案例分享,作者的核心成长平台 |
| 出海 AI Web 深海圈 | 生财有术内 | 出海 AI Web 专项学习圈,深度 SEO 课程 |
| 刘小排课程 | 公众号/生财 | 出海 AI Web 系统课程,专业性强,建议新手入门 |
| 哥飞出单群 | 微信群 | 哥飞组织的出单群友分享,实战交流 |
七、参考产品与案例
7.1 文章提及的优秀产品参考
文章提到了多个值得学习的产品案例,它们都体现了”简单易用”的产品设计原则。如 TinyPNG(熊猫压缩)、Remove.bg(一键去背景)、Typeless(用完有种不好意思不付费的感受)。另外提到的 Pollo AI,不是一开始就 all in one,而是因用户需求自然迭代而来。RoofClaw 案例($50k/月)证明了场景越垂直,付费率越高。
| 产品 | 地址 | 学习点 |
|---|---|---|
| TinyPNG | https://tinypng.com/ | 简单易用的典范,大名鼎鼎的熊猫压缩 |
| Remove.bg | https://www.remove.bg/ | 一键去背景,体验极简单 |
| Typeless | 搜索”Typeless” | 用完有种不好意思不付费的感受 |
| Pollo AI | 搜索”Pollo AI” | 不是一开始 all in one,用户需求自然迭代 |
| RoofClaw | 搜索”RoofClaw” | $50k/月,目标用户垂直场景(屋顶修复承包商) |
| Anybox | 搜索”Anybox” | 作者提到的优秀产品参考 |
| Google Wava | 搜索”Google Wava” | 反面案例,Google 也犯”大而全”的错误 |
7.2 播客推荐
文章末尾提到了正在听的播客《人何以自处》,由孟岩和李继刚主持,其中李继刚提出我们正处于三个世界的开启元年:现实世界(原子)、比特世界(互联网)和 AI 世界(向量),AI 时代会让时间变得不存在,这无疑会带来史无前例的机会。
八、核心方法论总结
8.1 产品设计三大原则
- 简单易用原则:把简单留给用户,把复杂留给自己,简单到爸妈一眼就能看明白
- MVP 原则:核心功能不能将就,要让用户有”诶哟不错”的 AHA Moment;可以粗糙,但核心功能要做到位
- 一句话原则:产品能用一句话说清楚它只做一件事,不要一上来就想着做 all in one
伟大不是被计划出来的,伟大是被迭代出来的。
8.2 流量四板斧
哥飞老师组织的出单群友分享中,有群友总结了”流量四板斧”:
- SEO
- 各大平台广告投流
- 红人传播
- 自己发帖灌水
核心还是围绕热点去做,跟炒股一样不干杂毛,只干龙头股。
8.3 新手破首单思路
新站付费率一般在 0.5%-1%,破首单意味着至少获得 200-300 个目标用户。把问题从”如何搞流量”转化为”从哪先搞到首批 300 个目标用户”,问题就变得具体多了。同时,如果答案还不够清晰,说明产品需求本身可能存在问题。
8.4 拉高付费率的关键策略
- 定价策略:发达地区用户,拉高客单价效果显著
- 想尽办法提高年订阅:默认选择最高年付费,年订阅价至少打 5 折以上(显示为月价),年订阅权益要比月度高很多
- 免费额度/试用设计:不是给时间,而是给用量——免费够让用户爽到,但不够让用户不付钱就满足
- 邮件召回:对已付费未续费、取消付费、留存好但未付费的用户进行邮件召回
- 用户证言:首页放真实用户评价,带头像和名字
- 限时优惠:制造紧迫感,有截止时间的折扣比常驻折扣高很多
- 沉没成本:让用户有参与感,付出时间成本
8.5 出海 Web 为什么值得做
亦仁观点:App 依赖投流,没有足够资金很难做大;出海 Web 不一样,小排老师就是典型的产品自驱动。
- 红利窗口期:很多国内公司还未涉及,停留在 App 领域
- 快速失败,快速验证需求:Web 迭代迅速,开发门槛和成本低,不需要折腾国内审核
- 躺赚,长期生意,边际成本低:订阅制 + Google 搜索机制,365 天 × 24 小时在线的”自动售货机”
没有任何捷径可以走,哪怕你再通过如何缜密的分析、推理,都无济于事。唯一的答案就是,停止空想,开始行动,不停地去折腾、试错、总结。 —— 小耳朵sir